
PARA 真的是 AI 時代的資訊管理關鍵嗎?
今天,提亞戈.佛特(Tiago Forte)在社群媒體 X 上發表了一篇引人注目的長文:〈Why PARA is the key to the AI era〉。身為「第二大腦」方法論的創始人,他的每一次發言都牽動著全球生產力愛好者的神經。
但這次,他的焦慮感比以往更明顯。
生產力教父的焦慮宣言
他提到,最近做了一件反常識的事:他刻意讓自己的電腦桌面和下載資料夾,整整一個月完全不整理,檔案就這樣堆著、散著、亂著。等到一個月後,他統計出一個非常醒目的數字:桌面與下載資料夾總共累積了 222 個檔案。
更重要的是,這 222 個檔案不是同質性的垃圾,而是跨越工作與人生的真實內容:財務文件(稅務、退休帳戶、保險表單)、工作素材(即將開課的宣傳圖、訪談錄影)、個人照片,以及各種他想讀、想研究的內容(例如一份談資訊過載的 PDF)。也就是說——這是一個人的生活正在運作時,自然會產生的資料碎片。
接著他做了第二步:把這 222 個檔案,全部用 PARA 的架構手動歸檔到他原本的檔案系統裡。結果讓他很得意,因為只花了 36 分鐘,換算下來平均每個檔案約 9.7 秒。
這個實驗的用意,不只是告訴你整理很快,而是為了鋪陳他後面的論點:即使 AI 可以幫你整理,整理依然值得你親手做,而且價值不在省時。
他要反駁的 AI 迷思:整理不是效率問題
提亞戈.佛特在這篇文章中,明確點出他看到的一種流行說法:很多人宣稱像 Claude Code 這類 AI 工具可以幫你把檔案整理好,所以檔案整理將會被 AI 取代——這好像是一個很直覺、很誘人的想像:人類終於不用再管那些瑣碎的歸檔。
但他認為,這個說法只抓到表面。他的核心反駁是:
整理真正的價值,從來不是效率或省時間;整理的價值在於整理這個動作本身,會觸發你的人類意識。
所以,他把整理重新定位成一種心理與認知層面的操作,而不是資料層面的搬運。
整理的三個非效率價值:提醒、清爽、保存
接著,提亞戈.佛特提出三個整理帶來的效果。而這三個效果,他強調都不是 AI 代勞就能同樣獲得的。
第一,整理會提醒你下一步要做什麼。 當他把一份 PDF 放進某個資料夾時,他會想起「這份我要寄給某個同事」;當他把某份文件歸位時,他會想起「我還要讀完並給回饋」;當他存下一張圖片時,他會想起「這是我想留著當設計靈感」。也就是說,整理不是把檔案搬走,而是讓你回到當初保存它的意圖。這個意圖往往只存在於你的腦內情境,而不是檔案內容本身。
第二,整理讓工作空間變得清爽,讓你更能專注。 他認為桌面或收件匣的混亂,會造成一種背景噪音——即使你沒有一直盯著它,你仍會感受到一種隱性的干擾。整理帶來的不是視覺整齊,而是心理的安靜;而心理安靜與創造力、專注感密切相關。
 ▲ 混亂的數位環境會持續消耗你的認知資源,整理帶來的不只是視覺整齊,更是心理上的安靜
▲ 混亂的數位環境會持續消耗你的認知資源,整理帶來的不只是視覺整齊,更是心理上的安靜
第三,整理是為了未來的可回收價值。 很多檔案不是當下要用,而是未來某一天會再用到,例如研究資料、可重複利用的素材或必須保存的合規文件。長期下來,這些累積成你的個人資料資產。
他最想強調的第四個價值:AI 時代讓整理更重要
上述三點其實就已經足夠成立,但提亞戈.佛特接著拋出他真正的主張:AI 時代出現了第四個理由,而且可能是最重要的理由。
整理,是為了讓你的資料能被更強大的 AI 使用。
他提醒讀者:AI 的出現,讓任何現成資料庫(包括我們電腦裡那些雜亂的文件)價值瞬間上升。因為 AI 可以用這些資料做很多事:寫作、分析、回顧、擴寫、總結、產生策略與產出文件。換句話說,你過去的那些資料,變成了可被再次利用的上下文礦藏。
但是,這裡有一個看似矛盾的地方:他也承認,你不需要先把資料整理得非常完美、非常一致,才能給 AI 使用;你可以把雜亂資料一股腦丟給模型,它也能處理。
嗯,那為什麼整理反而重要?
因為提亞戈.佛特認為 AI 工具有兩個現實限制,使得你必須能挑選出最該給它的那些內容:
- AI 的有效情境窗口有限,你不可能把整個人生資料一次餵進去。
- 搜尋只能找到相近檔案,但無法自動組成符合你工作方式的情境包。
所以,他主張:你需要事先被打包好的上下文,而 PARA 的四大類別恰好就是最自然的情境打包方式。
PARA 在 AI 協作裡扮演的角色:把散亂世界變成可指向的情境
提亞戈.佛特描述了一個很具體的挫折案例:他曾請 Claude 幫他寫一份給潛在客戶的提案,但 AI 需要找背景資料時就陷入困境——因為資料散落在 Google Drive、Notion 或部落格網頁等不同地方,連接器可能沒接上、權限可能卡住、甚至讀個網頁都會失敗。當你的上下文散落在十幾個平臺,每個平臺都像一座孤島,AI 做起事來就像到處撞牆。
而 PARA 的解法是:你不要讓 AI 去打獵,你要直接把獵物打包成一個可用的資料夾交給它。
- 你要 AI 幫你做某個專案 → 指向 Project 資料夾
- 你要 AI 幫你處理長期責任 → 指向 Area
- 你要 AI 幫你探索興趣 → 指向 Resource
- 你要 AI 幫你回顧過去 → 指向 Archive
這四種資料夾,等於是四種你的人生運作模式。換句話說,AI 要介入你的工作與生活,最需要的是你如何運作的框架,而不是檔案散落的碎片。
AI 仍然取代不了的部分,是重要性與聯想
最後,提亞戈.佛特回到他最想守住的一條底線:AI 目前還無法可靠做到的,是幫你判斷什麼重要、你接下來該做什麼,以及那些只有你才懂的聯想。
一個螢幕錄影檔,為什麼會讓你想起要寄給剪輯師?一堆照片,為什麼會讓你想到孩子下週要拍畢業照?一個舊的資料夾,為什麼會讓你突然想起我該把某些建議提供給朋友?
這些不是檔案本身能推論的,而是人類生活經驗和情境關聯的產物。AI 可以幫你做很多事,但它無法替你活過你的生活。
因此,他把這些想法收束成一句很簡單的結論:即使每個檔案平均要花十秒歸位,仍然值得,因為你整理的不是檔案,而是你的承諾、行動和生活結構。
他的核心主張,可以歸納為三層:第一,檔案組織的價值遠超過效率,它能提醒你該採取的行動、保持工作空間清爽、為未來保存參考資料。第二,AI 工具需要結構化的本地檔案作為上下文(context),而 PARA 的四個類別(Projects、Areas、Resources、Archives)恰好提供了最小可行上下文的預組裝包。第三,有些認知功能——例如從整理檔案的過程中觸發遠距聯想——是 AI 目前做不到的。
提亞戈.佛特的論述有其洞見,但感覺也有一些地方有待商榷。作為一位長期研究 AI 應用的講師與顧問,接下來我想從資訊科學、認知心理學和 AI 技術等三個維度,提供一份更完整的評估。
提亞戈.佛特說對了什麼?
公平地說,他的這篇文章的確觸及了幾個真實且重要的議題。
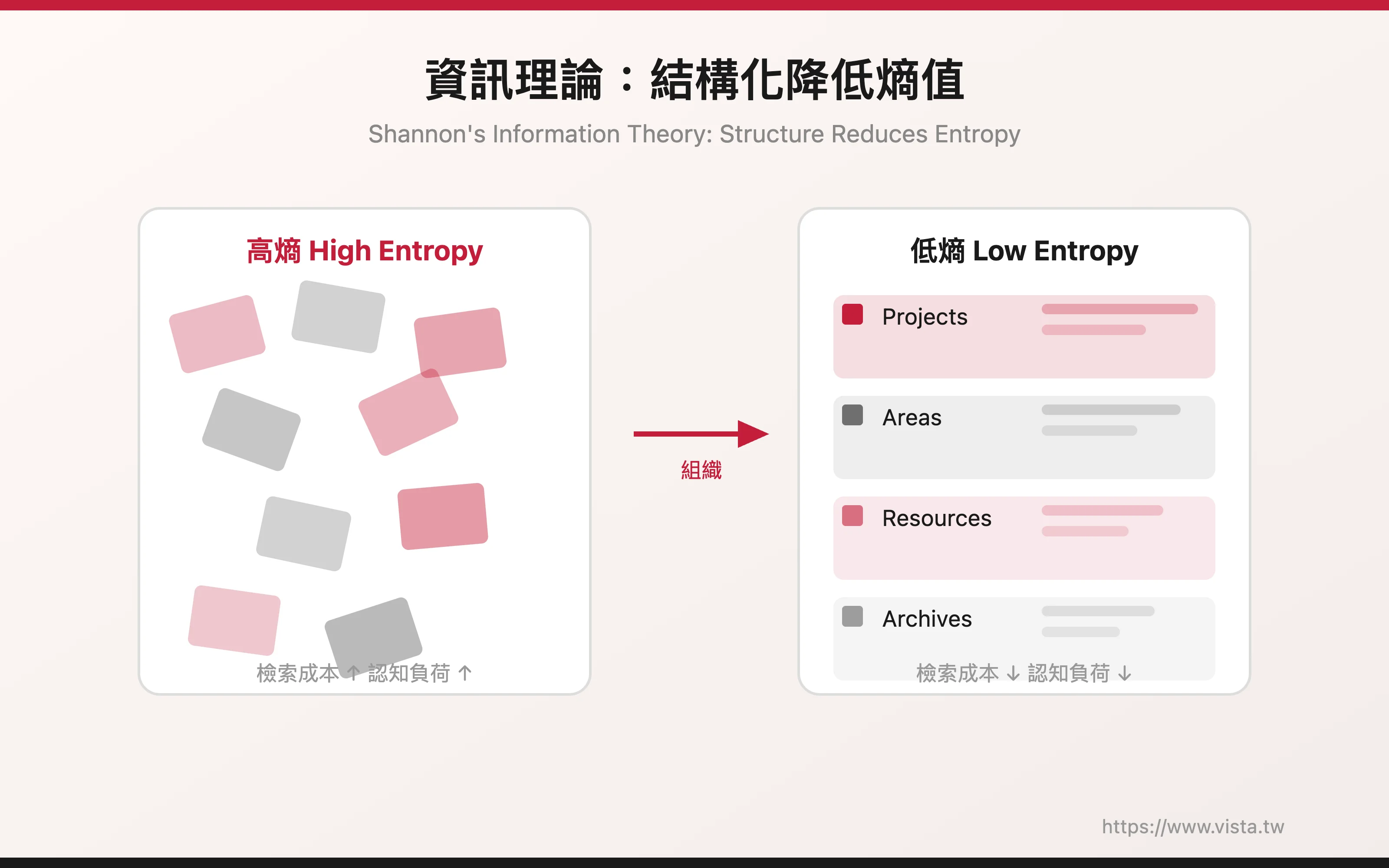 ▲ 夏農的資訊理論告訴我們,結構化資料能減少熵(entropy),降低未來檢索的認知成本
▲ 夏農的資訊理論告訴我們,結構化資料能減少熵(entropy),降低未來檢索的認知成本
首先,「組織不僅僅是效率」這個觀點,與資訊科學的基本原則高度一致。夏農(Claude Shannon)的資訊理論告訴我們,結構化資料能減少熵(entropy),讓系統更容易被導航和利用。當你把一份 PDF 歸檔到正確的專案資料夾時,你不只是在收納,而是在降低未來檢索的認知成本。
其次,他描述的「心理噪音」減少效應有堅實的科學基礎。注意力研究者羅伊.鮑邁斯特(Roy Baumeister)的自我控制理論(ego depletion theory)指出,意志力是有限的資源,而混亂的環境會持續消耗認知資源。美國普林斯頓大學的神經科學實驗也證實,視覺環境中的雜亂物品會競爭注意力資源,降低工作記憶的效能。保持數位桌面的整潔,確實能降低皮質醇水平、促進心流狀態(flow state)的進入。
第三,他強調組織過程能「提醒行動」,這精準呼應了心理學中的蔡加尼克效應(Zeigarnik Effect):未完成的任務會在記憶中持續活躍。
當你在桌面看到一段螢幕錄影,想起要寄給剪輯師——這種聯想確實是當前 AI 難以自主完成的。
第四,PARA 的「Archives」類別作為一種遺忘而不刪除的機制,類似人類長期記憶的運作方式。艾賓浩斯(Ebbinghaus)的遺忘曲線研究顯示,資訊會隨時間衰退,但適當的結構化儲存能在需要時重新喚醒它。這個設計確實優雅。
資訊科學的缺口:PARA 不是唯一解
然而,從資訊科學的角度來看,提亞戈.佛特的論述存在一個根本性的框架偏誤:他預設了階層式分類(hierarchical classification)是組織資訊的最佳方式,而忽略了現代資訊架構的多元方法論。
PARA 本質上是一個四層的階層結構,但現代資訊檢索系統早已超越這種典範。標籤系統(tagging)允許同一份文件屬於多個類別,解決了階層結構中「這份文件該歸到 Projects 還是 Resources?」的經典困境。圖形資料庫(graph databases)能捕捉檔案之間的語義關係,而不僅是歸屬關係。全文搜尋引擎(如 Elasticsearch)能在非結構化資料中進行語義搜尋,根本不需要預先分類。
更關鍵的是,他在文章中聲稱「搜尋只能找到個別檔案的精確匹配」,如今這個說法可能已經過時。向量搜尋(vector search)和語義嵌入(semantic embeddings)技術——透過 FAISS、Pinecone、Chroma 等向量資料庫——能夠理解查詢的語義意圖,找到概念相關但文字不同的文件。當你搜尋「客戶提案策略」時,系統能找到標題為「Q3 Business Development Plan」的文件,即使兩者沒有任何共同關鍵字。
這意味著,AI 時代真正需要的可能不是更精細的資料夾結構,而是更豐富的後設資料(metadata)和語義索引。
PARA 提供的是一種人類可讀的組織框架,但對 AI 而言,一個被良好標記和嵌入的平面檔案系統(flat file system),可能比四層資料夾更高效。
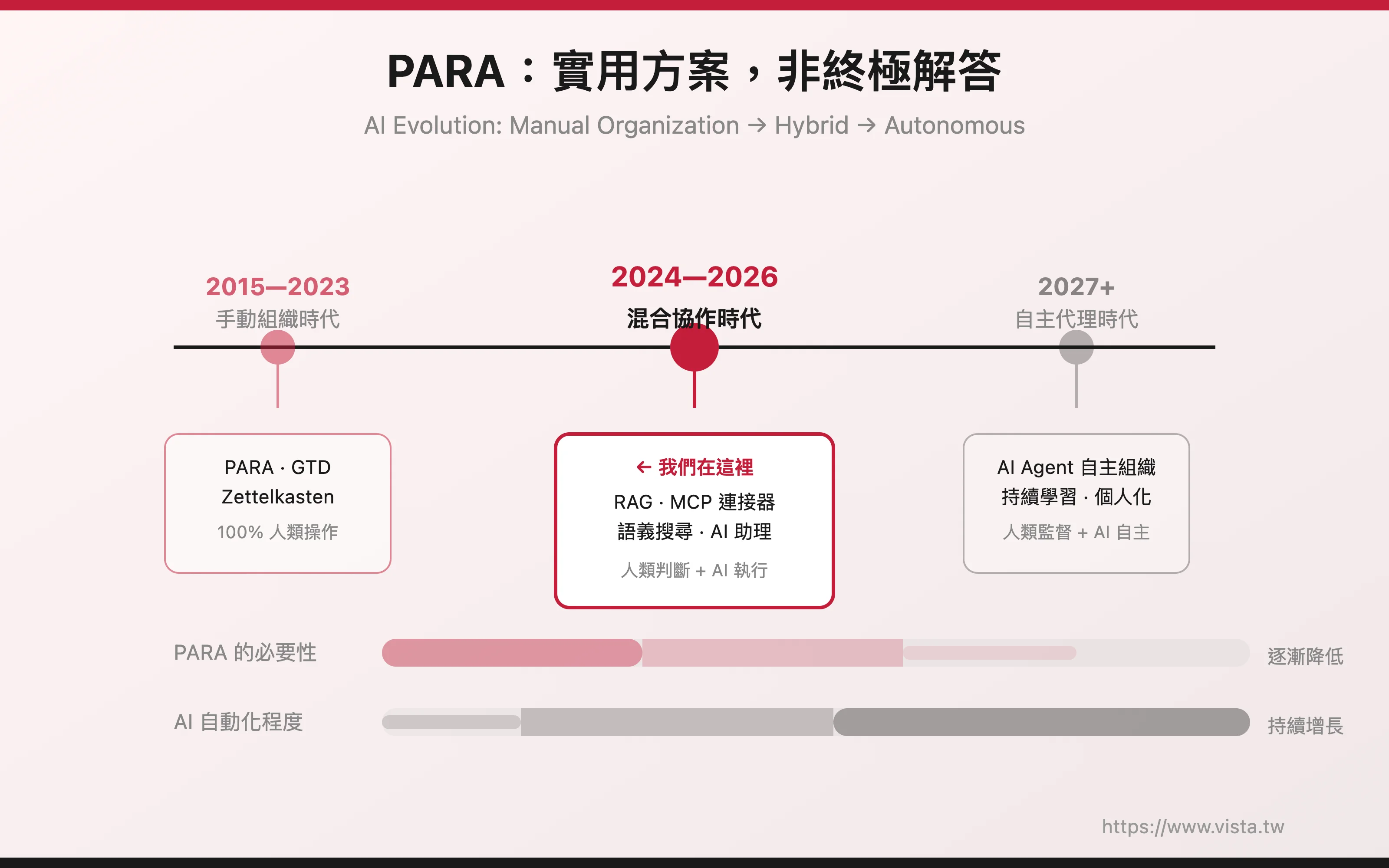 ▲ PARA 是有效的過渡方案,但從 AI 技術發展來看,它可能不是終極解答
▲ PARA 是有效的過渡方案,但從 AI 技術發展來看,它可能不是終極解答
心理學的補充:被忽略的個體差異
提亞戈.佛特的心理學論述雖然方向正確,但有可能犯了一個常見的錯誤,也就是將自己的認知風格推廣為普世法則。
 ▲ 五大人格特質模型提醒我們,組織行為的效益因人而異——有些人反而在「受控的混亂」中更有創意
▲ 五大人格特質模型提醒我們,組織行為的效益因人而異——有些人反而在「受控的混亂」中更有創意
人格心理學中的五大人格特質模型(Big Five)提醒我們,組織行為的效益因人而異。高神經質(neuroticism)且高嚴謹性(conscientiousness)的人,確實能從結構化系統中獲得安全感和效能感。但高開放性(openness)的人可能發現,過度組織反而限制了創意的自由聯想。某些創意工作者刻意維持受控的混亂(controlled chaos),因為隨機的並置能激發意想不到的連結。
此外,他在文章中提到的每項工作耗時約 9.7 秒的計算,有可能忽略了機會成本和決策疲勞(decision fatigue)。心理學家凱斯琳.沃斯(Kathleen Vohs)的研究顯示,每一次分類決策都會消耗有限的認知資源。222 個檔案的存在,意味著 222 次「這該放哪裡?」的微決策。對某些人來說,這 36 分鐘的認知負荷可能抵銷了整理帶來的心理清爽感。
更值得關注的是數位失憶(digital amnesia)的風險。貝斯提.史巴洛(Betsy Sparrow)等人在 2011 年發表於《Science》的研究發現,當人們知道資訊被外部系統儲存時,會降低對該資訊的記憶編碼努力。過度依賴任何組織系統——無論是 PARA 還是 AI——都可能弱化我們的元認知(metacognition)能力,也就是知道自己知道什麼的能力。
PARA 很實用,但未必是終極解答
這是我認為提亞戈.佛特的論述最需要被挑戰的地方。他將 PARA 定位為 AI 時代的關鍵,但從 AI 技術發展的軌跡來看,PARA 的確很實用,但更像是一個過渡方案。
首先,他可能低估了 AI 處理混亂資料的能力。他在文章中承認你可以把資料以其混亂的榮耀提供給大型語言模型,但隨即論證還是需要預先組織。然而,現代 AI 工具鏈已經具備自動化組織的能力。LangChain 和 Semantic Kernel 等框架可以掃描整個目錄、提取語義和自動分群。多模態模型能同時分析圖像、PDF 和文字的語義關聯。RAG(Retrieval-Augmented Generation)架構讓 AI 能從大量非結構化資料中精準提取相關上下文,而不需要人類預先將檔案放入正確的資料夾。
提亞戈.佛特在文章中所描述的「Claude 試圖幫我寫提案但找不到相關資料」的經驗,反映的不是 PARA 的必要性,而是當前 AI 工具在跨平臺整合上的暫時局限。這個問題正在被快速解決——Apple Intelligence 的裝置端語義搜尋、Windows Copilot+ 的 Recall 功能、以及各種 MCP(Model Context Protocol)連接器,都在朝向讓 AI 無縫存取你所有資料的方向推進。
再看他說「AI 無法做到遠距聯想」這一點。這在技術層面是部分正確的——當前的大型語言模型確實缺乏持續的情境意識(persistent situational awareness)。但這個限制正在被記憶系統(memory systems)、個人知識圖譜(personal knowledge graphs)和代理架構(agent architectures)逐步突破。未來的 AI 助理很可能在你整理度假照片時,主動提醒你「你的朋友 David 正在規劃類似的旅行,要不要把推薦清單寄給他?」
這不是科幻想像,而是目前已經在開發中的功能方向。
透視動機:為什麼提亞戈.佛特這樣說
如果想要真正理解提亞戈.佛特的這篇文章,不能忽略他的身份背景。
他的整個事業版圖——書籍、線上課程、認證教練培訓、Forte Labs 的付費內容——都建立在 PARA 和「第二大腦」方法論之上。當 AI 工具被市場宣傳為能自動組織你的檔案時,有可能會影響他的核心價值主張。
所以,這篇文章本質上是一次精巧的品牌重新定位:不是否認 AI 的能力,而是將 PARA 從組織方法升級為 AI 時代的基礎設施。他的論證策略是先承認 AI 能做很多事,然後論證 PARA 讓 AI 做得更好,最後補上但有些事 AI 做不到作為安全網。
當然,這不是說他的觀點沒有價值。因為,他確實指出了一些真實的問題。但讀者應該掌握清楚的脈絡,並做出適合自己的抉擇。打個比方,一個真正中立的分析可能會得出不同的結論:也許 AI 時代需要的不是 PARA,而是一種全新的人機協作組織典範。
我的觀點:擁抱混合策略,拒絕單一教條
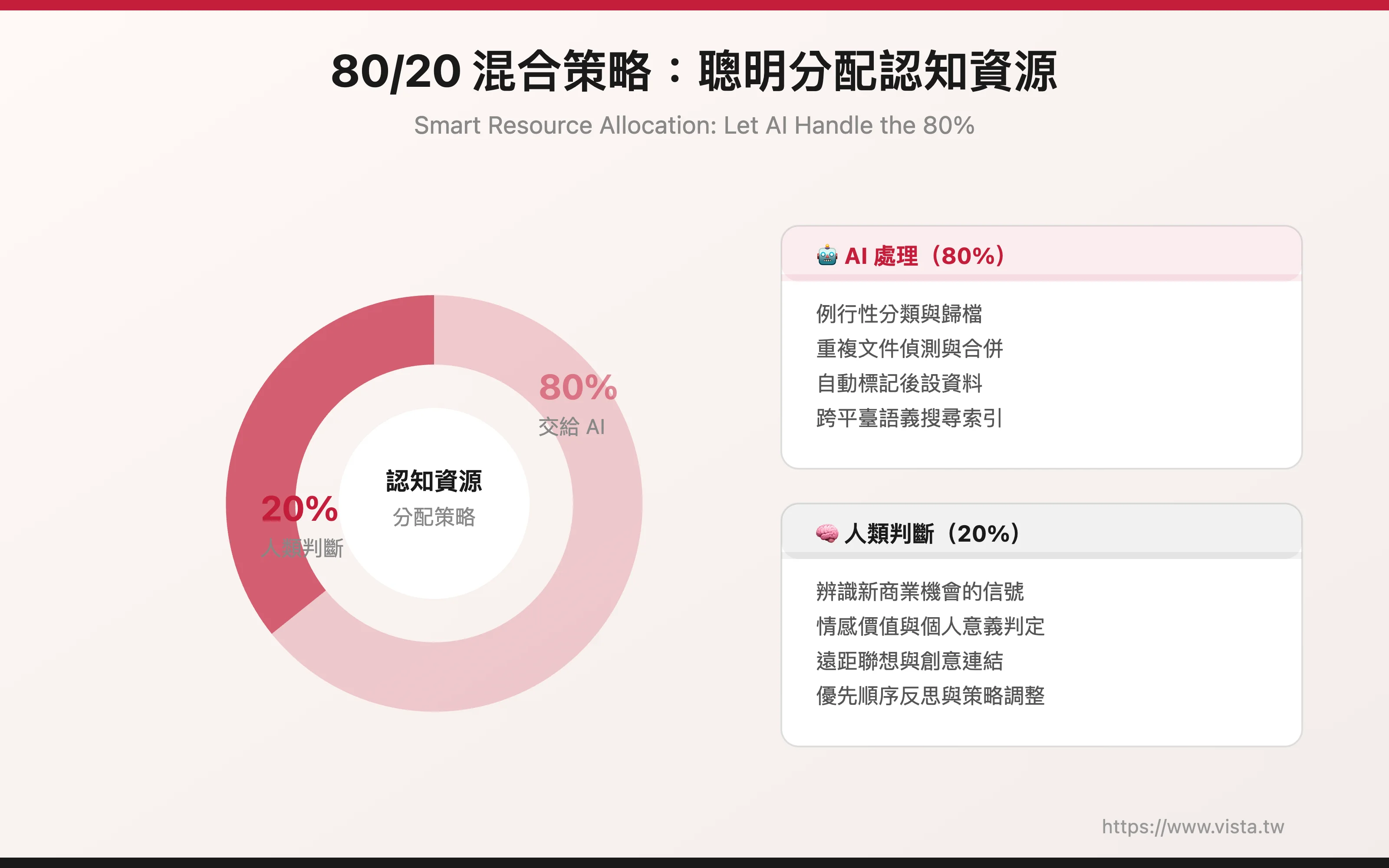 ▲ 把 80% 的例行分類交給 AI,將認知資源保留給那 20% 真正需要人類判斷的決策
▲ 把 80% 的例行分類交給 AI,將認知資源保留給那 20% 真正需要人類判斷的決策
基於以上分析,我認為 AI 時代的個人資訊管理,也許需要的不是對任何單一系統的忠誠,而是一種靈活的混合策略。以下是我的具體建議:
 ▲ AI 時代的個人資訊管理,需要的不是對單一系統的忠誠,而是靈活的混合策略
▲ AI 時代的個人資訊管理,需要的不是對單一系統的忠誠,而是靈活的混合策略
第一,建立語義優先的組織習慣。與其把精力花在決定檔案該放進哪個資料夾,不如投資在豐富每份文件的後設資料上——標題要有描述性、內容要有摘要、標籤要反映多維度的關聯。這對人類和 AI 都更有價值。
第二,善用 AI 的自動化能力來處理 80%。大多數檔案的分類是例行性的,完全可以交給 AI。把你的認知資源保留給那 20% 真正需要人類判斷的決策——例如,某份文件是否代表一個新的商業機會,或某張照片是否有情感上的特殊意義。
第三,定期進行數位回顧,而非只是數位整理。他的 9.7 秒歸檔法關注的是把東西放對地方,但更有價值的做法可能是定期瀏覽你的數位資產,問自己:「這些東西告訴我什麼關於我目前的優先順序?」這種反思性回顧(reflective review)才是 AI 無法替代的認知活動。
第四,投資跨平臺的語義搜尋工具。與其試圖把所有東西集中到本地資料夾,並且整理出完美的架構,不如善用能跨平臺搜尋的語義工具。技術正在朝這個方向快速發展,早期採用者將獲得巨大的生產力紅利。
第五,保持對任何系統的健康懷疑。無論是 PARA、GTD(Getting Things Done)還是任何新興的 AI 驅動方法論,都只是工具,而不是信仰。我必須說,我很喜歡這些工具!但是,最好的系統是你願意持續使用、並且能隨著技術和需求演變而調整的系統。
第六,培養你的元認知能力。在 AI 愈來愈擅長代替我們記憶和組織的時代,人類最珍貴的能力是知道何時該信任系統、何時該信任直覺。
這種判斷力無法被外包,也不應該被任何系統取代。
在秩序與混沌之間
老實說,提亞戈.佛特的焦慮是可以理解的——當你花了十年建立一套方法論,看到 AI 可能讓它變得不再必要,自然會想為它找到新的存在理由。但歷史告訴我們,每一次技術變革都會淘汰一些方法、保留一些原則。
PARA 的核心原則——以行動為導向的組織、適時遺忘的智慧、個人化的資訊架構——這些在 AI 時代依然有價值。但是諸如手動歸檔到四個資料夾的具體實踐方式,很可能在未來幾年被更智慧的人機協作模式取代。
所以,就我看來,真正的問題不是 PARA 是不是 AI 時代的關鍵?而是在 AI 愈來愈聰明的時代,人類應該把認知資源花在什麼地方?我的淺見是花在判斷、反思和創造上,而不是花在把一個個檔案拖進資料夾裡。
讓 AI 處理秩序,讓人類擁抱有意義的混沌。
延伸閱讀:
- Anytype + Claude:打造 AI 驅動的第二大腦,讓你的筆記活起來
- AI 筆記除了快,更是幫你建立長期優勢的祕密武器
- 別讓你的努力被遺忘,巧用 AI 打造職涯的第二大腦
- 讓 AI 成為思考夥伴,而非只是產製答案的機器
- 認知差才是真正的財富密碼
外部資源:
- Why PARA is the key to the AI era(Tiago Forte 原文)
- Building a Second Brain 官方網站
- The PARA Method: A Universal System for Organizing Digital Information


